Smart Review Summarization Project
Early this year, my friends in Machine Learning Study Group and I were learning natural language processing. To make the learning experience more interesting, we thought we could strike a real life project; three of us are online shoppers and all know the pain of scanning through lots of reviews before placing purchasement. What if there’s a tool that can summarize all the thousands of reviews for us? So we started.
Here I present our joint work SRS, srs.mit.edu, which is to save us. By using Natural Language Processing and Machine Learning techniques, SRS is able to instantly help summarize customers’ opinions on various aspects of a particular product. On top of that, it also enables users to compare sentiment scores for two similar products.
Workflow
An SRS user is only required to type in a product ID or product URL from Amazon, the rest of work will be taken care of by SRS internal workflow.
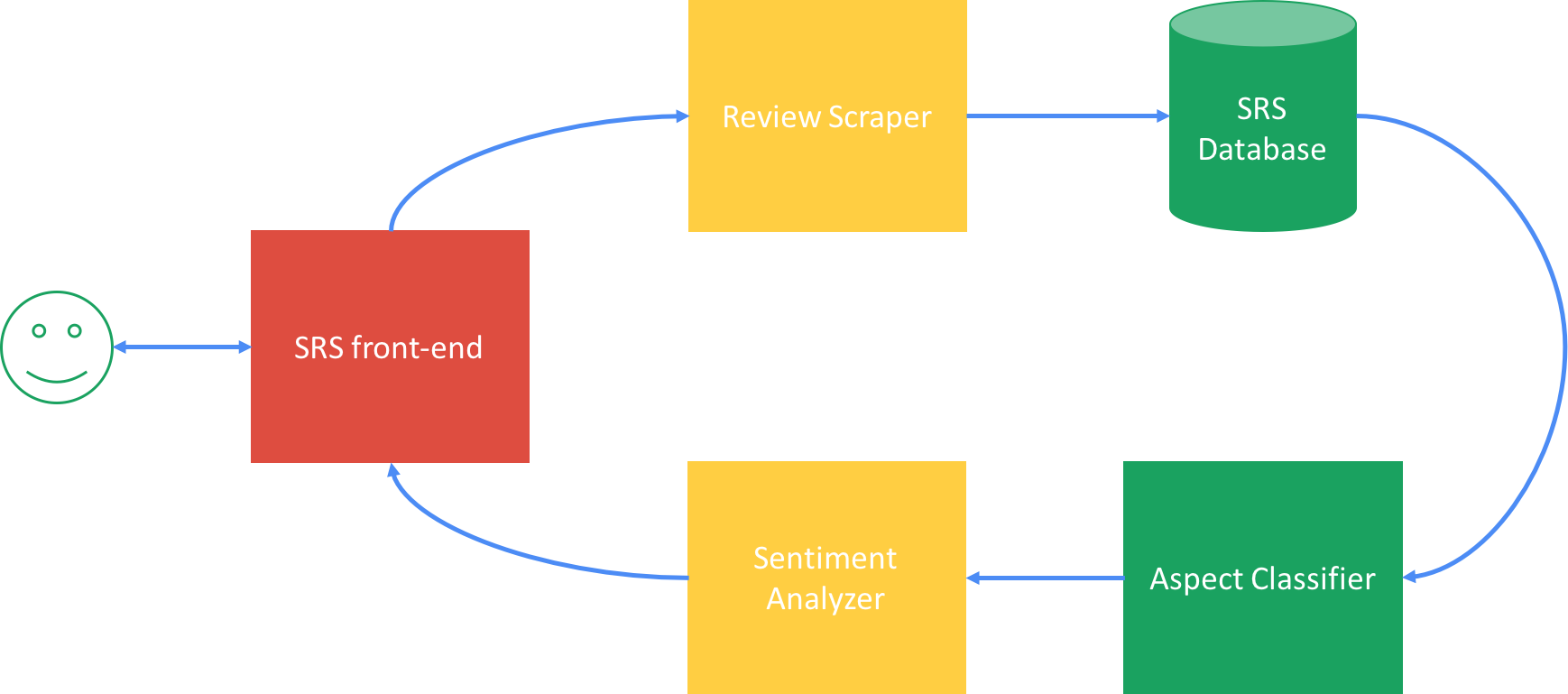
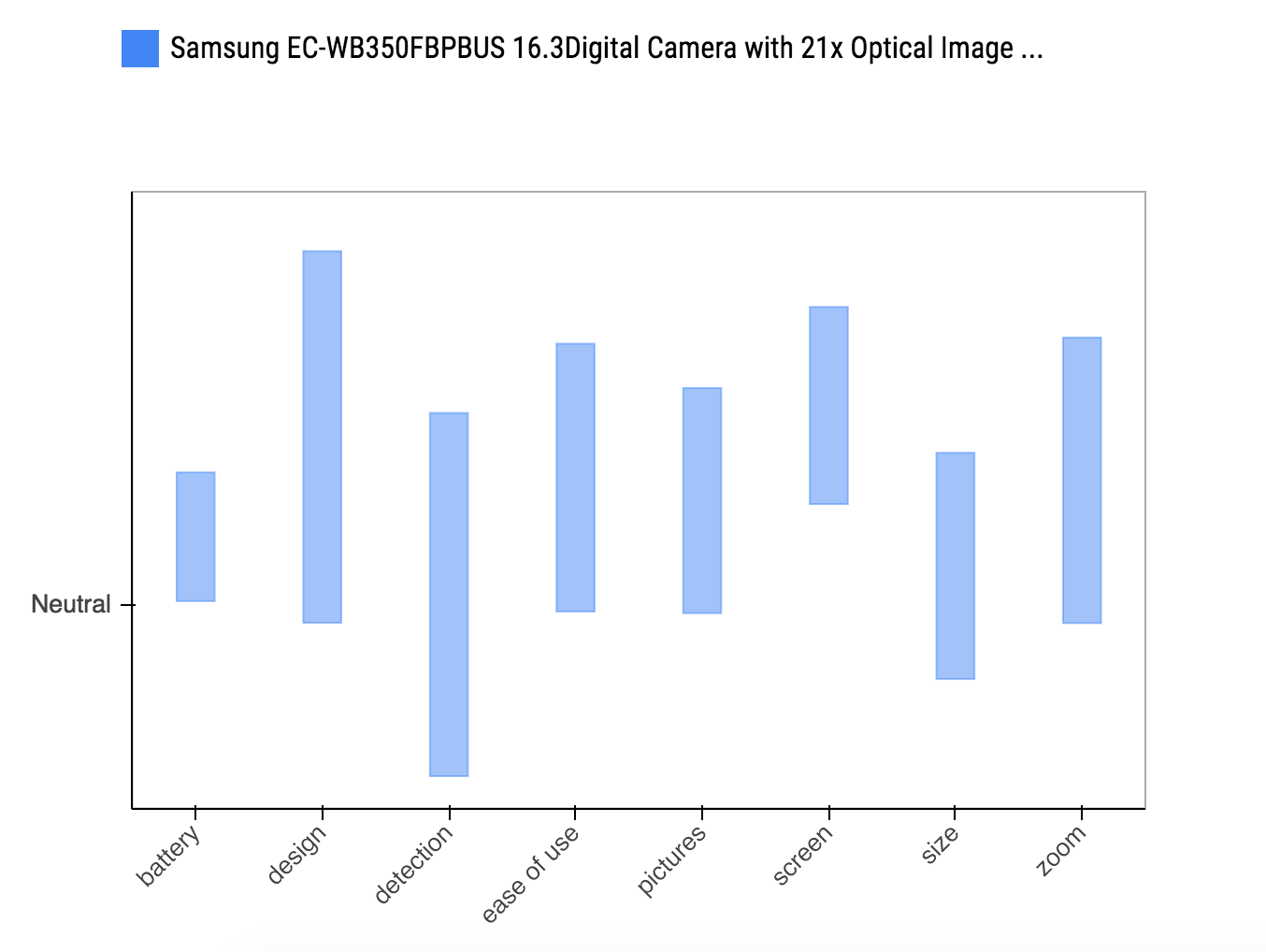
Once SRS front-end gets user query, it invokes Review Scraper to work, which collects reviews and stores into SRS Database. Then Aspect Classifier starts to analyze each sentence in the reviews, classifying which aspects the review is discussing (e.g., I like this camera, it can last whole day without re-charging will be classified as battery). Later sentiment analyzer aggregates review positivity for each aspect and send the summary to SRS front-end to present. A typical summary box plot is shown below.
Review Scraper
Once user requests for a product, Review Scraper will first be triggered if the product is not recorded before in database. By using python-amazon-simple-product-api, Review Scraper is able to scrape reviews page by page.
This process can be fairly long especially for products with thousands of reviews. A time limit of 30 seconds is set and top helpful reviews are first scraped so that users can get most relevant information within reasonable time. In order to make reviews gradually complete, Review Scraper is able to continue scraping from where previous scraping stops. Once a product’s reviews are considered complete (a certain ratio between number of reviews in database and total number of reviews online), future requests for that product don’t trigger Review Scraper any more.
Aspect Classifiers
One review usually contains many points, covering more than one aspects of a product. One of the biggest values this project creates is provide sentiment scores for each aspect of the product so that users are informed in a much deeper level compared with given an overall score. So the most crucial part of SRS is to classify each sentence into several aspects.
Currently, we’ve designed an extensible classification framework with three interchangeable classifiers: maxEntropy, word2vec, word2vec_svm.
maxEntropy
Maximum entropy is a supervised learning algorithm that often used in text classification. The idea of maximum entropy in classification is similar to that of the Naive Bayes that they are both discriminative model that estimate the conditional probability
\[P(a|s)\]of each predefined product aspect given a sentence/fragment from review. Unlike Naive Bayes, maximum entropy does not hurt by strong independence assumption in the presence of overlapping features that defines the product aspect. For example, if the word shoot is a feature for product aspect picture and video, then maximum entropy could naturally handle this during training of parameters.
The conditional probability in maximum entropy is a parameterized exponential distribution or more precisely it called maximum entropy probability distribution.
\[P(a_i|s_j) = \frac{\mathrm{exp}( \lambda_i^\intercal f_i(s_j,a_i))}{\sum_{i} \mathrm{exp}(\lambda_i^\intercal f_i(s_j,a_i))}\]Where \(\lambda_i\) is a vector of parameters for aspect \(i\), \(f_i\) is a vector of feature. The choice of feature is arbitrary and the text classifier will yield the best result when chosing key words relevant to the product aspect. Currently, we defined the feature space based on first 20 key words in the tf-idf ranking and the their values are simply the occurrence of the chosen key words. Choice of feature space can definately exploited to further improve classification in the future. During the training process, the parameter matrix \(\Lambda\) is to be determined by minimizing the negative log of the sum of conditional probability for all sentences assuming all sentences are independent of each other.
The maximum entropy has yields a satisfactory accuracy (>60%) that is used as a benchmark for comparing other text classification algorithms.
Sentiment Analyzer
After classification, all the review sentences are grouped by aspects. Sentiment Analyzer is designed to go through sentences aspect by aspect and assigns sentiment scores for each single sentence. Eventually each aspect has a distribution of sentiment, which makes it ready for final rendering in SRS front-end as well as comparison with another product if necessary.